Segment and Track Anything.
25 May 2023Track Anything (TAM)の2週間後に出たSAM x 物体領域追跡の論文.初期マスクをSAMで,追跡は既存追跡器でという構成はTAM同様.自然言語によるプロンプティングができること,新物体を自動追加できることが新しい.
基本情報
@misc{cheng2023segment,
title={Segment and Track Anything},
author={Yangming Cheng and Liulei Li and Yuanyou Xu and Xiaodi Li and Zongxin Yang and Wenguan Wang and Yi Yang},
year={2023},
eprint={2305.06558},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
論文リンク
著者・所属
- Yangming Cheng, Liulei Li, Yuanyou Xu, Xiaodi Li, Zongxin Yang, Wenguan Wang, Yi Yang
新規性
発想,手法的に最も近いと思われるTAMとの主な差分は次の2点:
- 初期マスクを与える際に自然言語のプロンプトを与えることができる
- 新物体を自動追加できる
手法
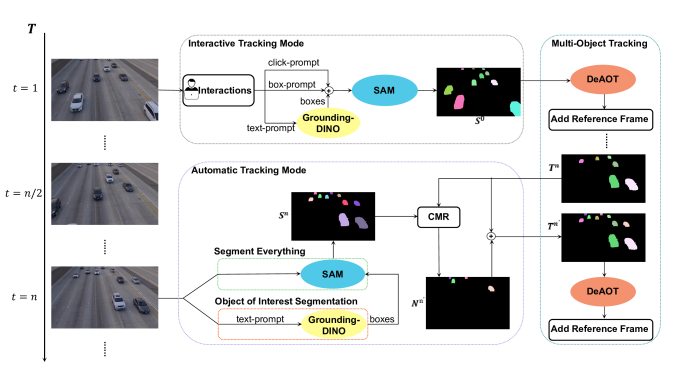 |
|---|
| 原論文Figure 1. |
- 自然言語のプロンプトはSAM論文でやっていたようにそのまま与えるのではなく,Grounding-DINOでバウンディング・ボックスに変換し,そのバウンディング・ボックスをプロンプトとしてSAMに入力する
- 生成した初期マスクからの時間発展はDeAOTに任せる
- 一定時間おきに動画に現れた新しい物体のマスクを追加する
- SAMの予測とDeAOTの出力の重なりが小さい物体が「新しい物体」であると判定する
- TAMと違い,追跡中の物体マスクを補正することはしない
結果
DAVIS-2016(単一物体追跡), DAVIS-2017(複数物体追跡)でDeAOTと同等の追跡精度を達成している.
議論・コメント
初期マスクの生成を除き,追跡自体はDeAOTに任せているので,DeAOTと同等の定量評価結果となるのは(SAMが十分に高品質な初期マスクを生成できるという仮定のもとで)ある意味当たり前.それだけに,やはりなぜTAMの精度があそこまでベースのXMemより低かったのかが気になってしまう.
人による介入(初期マスク生成や途中での人力補正)が容易になるメリットは小さくないが,TAMも含めてSAMを使うことによる高精度化まではできていない.まだまだ研究の余地があると思う.
関連文献
Tags
foundation models video vision&language video object segmentation