Track Anything
25 May 2023Segment Anything Model (SAM) を使って物体領域追跡問題を解く論文.物体領域追跡では初期マスクを与えるが,SAMによって少数のクリックで高品質な初期マスクを与えられる他,領域マスクの自動補正や人間による途中介入が可能になる.
基本情報
@misc{yang2023track,
title={Track Anything: Segment Anything Meets Videos},
author={Jinyu Yang and Mingqi Gao and Zhe Li and Shang Gao and Fangjing Wang and Feng Zheng},
year={2023},
eprint={2304.11968},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
論文リンク
著者・所属
Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, Feng Zheng (SUSTech VIP Lab)
新規性
動画タスク,特に物体領域追跡(Video Object Segmentation, VOS)にSAMを適用した.
SAMをフレームごとに適用する単純な方法では,物体マスクの時間的整合性,つまりフレーム間の滑らかな追跡ができない.そこで,SAMとVOSのSOTA手法 XMem を組み合わせることで,VOSにSAMを適用することに成功した.
従来のVOSと比較すると,SAMを導入したことで次のような利点がある:
- 高品質な初期マスクを数クリックのプロンプトで生成できる
- 長時間の追跡により劣化したマスクをSAMで補正できる
- 途中で容易に人が介入できる
手法
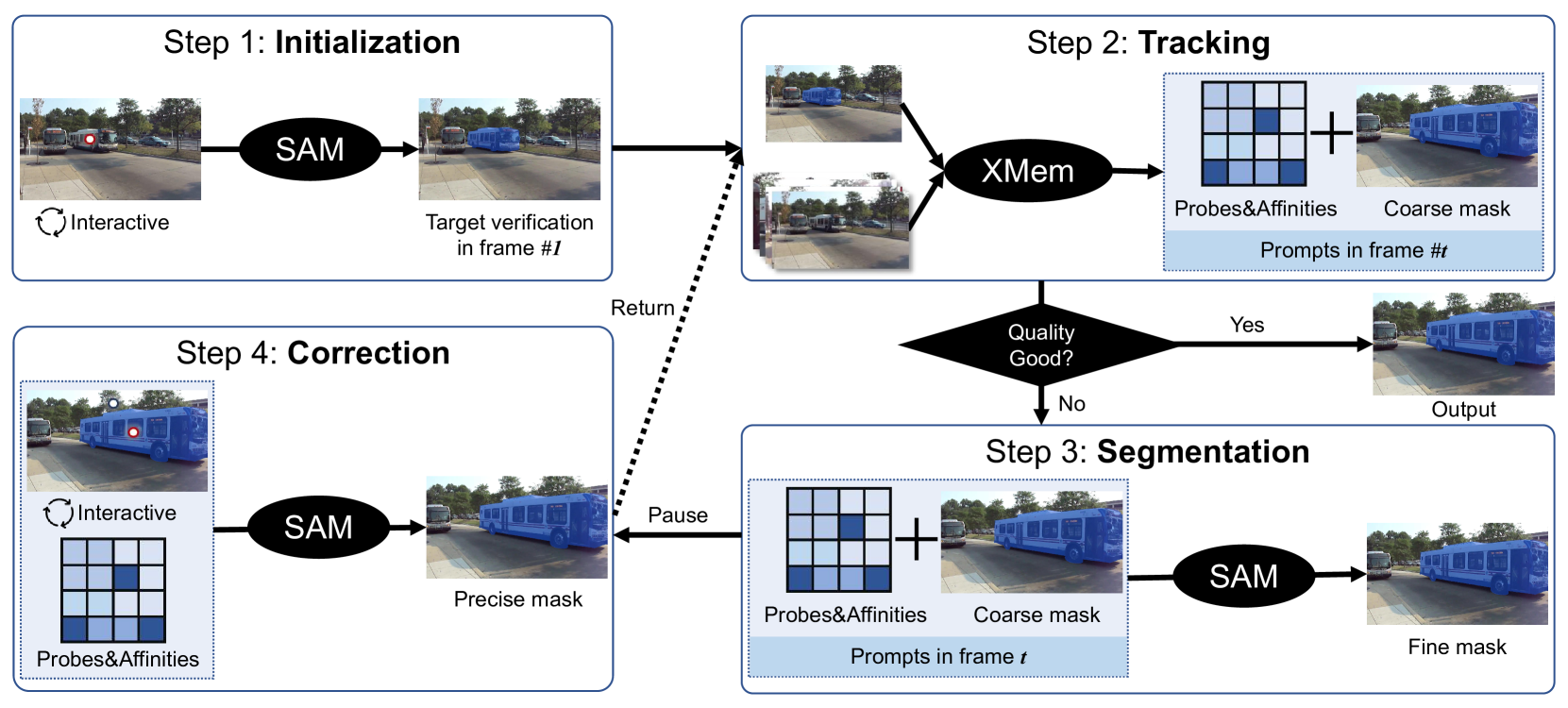 |
|---|
| 原論文Figure 1. |
- SAMで初期マスクを生成する
- 1.の結果を元にXMemで追跡する
- 追跡したマスクの品質をモニタリングし,劣化が進んだらSAMで補正する
- 補正には,その時点での物体マスクと,XMemの内部状態から予測した前景点をプロンプトとして与える
- 必要に応じて中断し,人手でSAMを使って補正する
結果
単一物体追跡(DAVIS 2016)と多物体追跡(DAVIS 2017)で評価.最新のXMemやAOTには劣るが,4年くらい前のSOTAに匹敵する精度.
議論・コメント
ベースになっているXMemよりも精度がかなり劣化しているのが気になる.初期マスク生成を除き追跡自体はXMemが行っていることを考えると,可能性は2つ:
- 初期マスクの品質が悪すぎる
- 中間での自動補正が悪さをしている
後続のSAM-Trackが自動補正しない点を除いて同じ発想の手法を提案しており,そちらはベースのトラッカーと同等精度を出していること,初期マスクの品質が悪ければ十分に良くなるまでSAMプロンプトを与えることもできることを考えると,自動補正が悪さをしている可能性が高い?それとも,初期マスクの品質に関係なく単一クリックプロンプトなどの制約を課している?(読み取れなかった)
関連文献
- XMem
- SAM-Track
Tags
foundation models video video object segmentation