Grounded Language-Image Pre-training
05 Jul 2023文中の句と画像中の物体との対応を推定するphrase groundingタスクの大規模事前学習GLIPを提案.Groundingの教師あり学習した教師モデルでcaptioningのデータセットにボックスの疑似ラベルを付与し,疑似大規模データを生成,それを使った自己学習が効果的.
基本情報
@InProceedings{Li_2022_CVPR,
author = {Li, Liunian Harold and Zhang, Pengchuan and Zhang, Haotian and Yang, Jianwei and Li, Chunyuan and Zhong, Yiwu and Wang, Lijuan and Yuan, Lu and Zhang, Lei and Hwang, Jenq-Neng and Chang, Kai-Wei and Gao, Jianfeng},
title = {Grounded Language-Image Pre-Training},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10965-10975}
}
論文リンク
著者・所属
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, Jianfeng Gao (UCLA, Microsoft Research, University of Washington)
新規性
- 物体検知をphrase groundingタスクとして再定式化することで物体検知と根拠推定(grounding)を統合
- 人手でアノテーションしたバウンディングボックス付きのデータに加え,ウェブから収集した画像・テキストペアの大規模データセットにボックスの疑似ラベルを付与することでデータセットを増強することが効果的であることを示した
手法
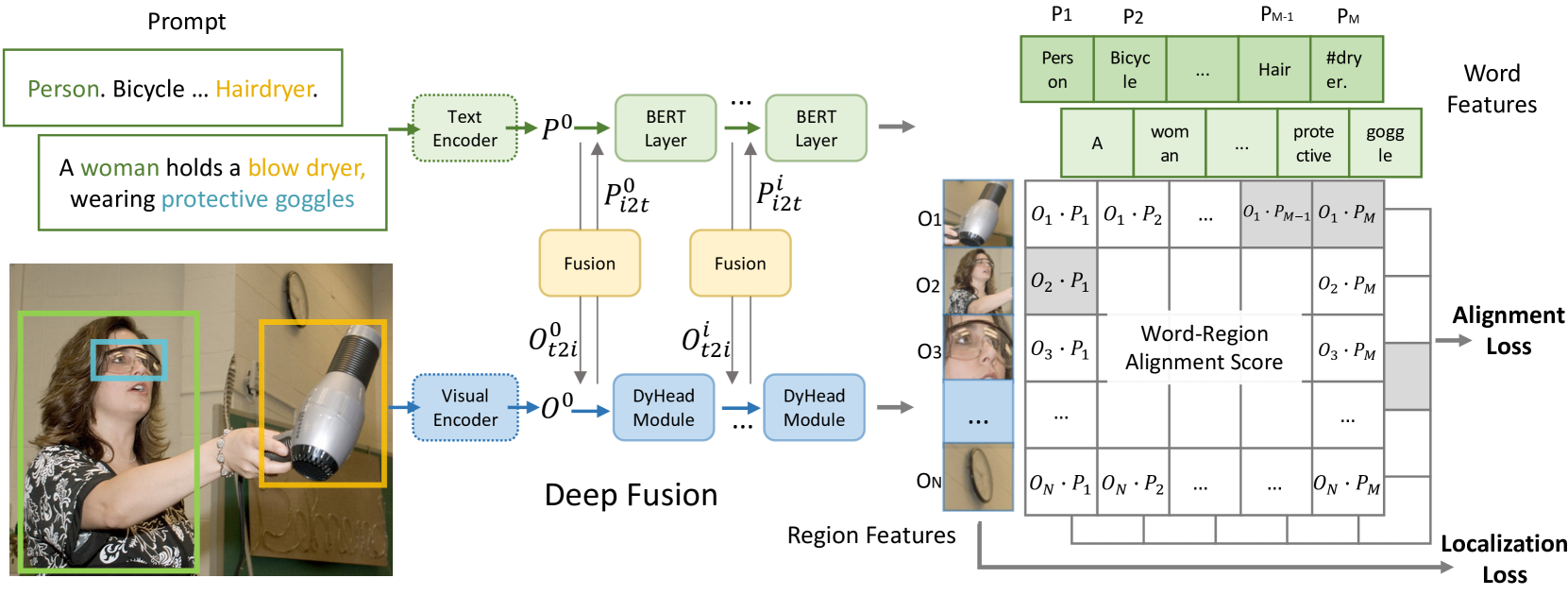 |
|---|
| 原論文のFigure 2.モデルの概要. |
- Groundingのalignment loss:テキストエンコーダに符号化されたテキストのフレーズ特徴量と,視覚的エンコーダに符号化された物体領域の特徴量とを整合させる
- 「入力テキストに含まれる複数のフレーズ」対「入力画像に含まれる複数の領域」のマッチングである点に注意
- cf: CLIP:バッチ中の画像特徴量とキャプション特徴量との対照学習
- 物体検知は,テキスト入力として "Detect: person, bicycle, ..., "のようなプロンプトを与えたgroundingとして定式化できる
- Groundingの正解データを使った教師あり学習
- 根拠推定と物体検知の正解付きデータセットで学習
- 物体検知データは上記のやり方で根拠推定のデータセットとして利用する
- Captioningのデータを使った自己学習
- 教師あり学習で学習した教師モデルを使ってキャプショニングのデータセットにボックスの疑似ラベルを付与
- 疑似ラベル付きデータも合わせて生徒モデルを学習
結果
議論・コメント
- 転移学習としてはゼロショットというよりはドメイン転移に近い
- 事前学習データのカバー範囲が広くターゲットクラスを含んでいるかもしれないから
- この考え方はOpen-vocabularyに近い
- 事前学習データのカバー範囲が広くターゲットクラスを含んでいるかもしれないから
- Open-worldとは少し違う
- Open-world:テスト時に未知クラスが来たことを検知する
- 本論文の設定:未知・既知の区別なく(言語モデルが知っている語なら?)言われたものを何でも検知する
- 物体検知をgroundingとして定式化すること自体は当たり前のように思ったが,そうすることでキャプショニングのデータセットにボックスの疑似ラベルを張れるようになって,大規模学習できるようになるというアイデアがかなり面白いと思った
- Promptチューニングがfull model tuningに匹敵する精度出ているのは興味深い
関連文献
- MDETR
Tags
foundation models vision&language object detection