GLIPv2: Unifying Localization and Vision-Language Understanding
05 Jul 2023根拠推定による事前学習で局在化の精度向上を示したGLIPを拡張し,VQA,captioning等の理解タスクにも適応させたGLIPv2を提案.v2ではある画像中の物体領域と別の画像のキャプションとの間で対照学習を行うinter-image region-word contrastive learningを導入.単一のGLIPv2モデルが多くのタスクでSoTAに近い性能を達成した.
基本情報
@inproceedings{NEURIPS2022_ea370419,
author = {Zhang, Haotian and Zhang, Pengchuan and Hu, Xiaowei and Chen, Yen-Chun and Li, Liunian and Dai, Xiyang and Wang, Lijuan and Yuan, Lu and Hwang, Jenq-Neng and Gao, Jianfeng},
booktitle = {Advances in Neural Information Processing Systems},
editor = {S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh},
pages = {36067--36080},
publisher = {Curran Associates, Inc.},
title = {GLIPv2: Unifying Localization and Vision-Language Understanding },
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/ea370419760b421ce12e3082eb2ae1a8-Paper-Conference.pdf},
volume = {35},
year = {2022}
}
論文リンク
著者・所属
Haotian Zhang, Pengchuan Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, Jianfeng Gao (University of Washington, Meta AI, Microsoft, UCLA)
新規性
新規性というよりGLIPとの差分を挙げると:
- v2では局在化以外の下流タスク(VQA,captioning)も対象とする
- v2では画像間で物体領域とフレーズをマッチさせる対照学習inter-image region-word contrastive learningを実施する(v1では画像内で)
- v2では単一のモデル(パラメータも同じ)が多数のタスクを解けることを実証(v1ではタスクごとにチューニングが必要)
手法
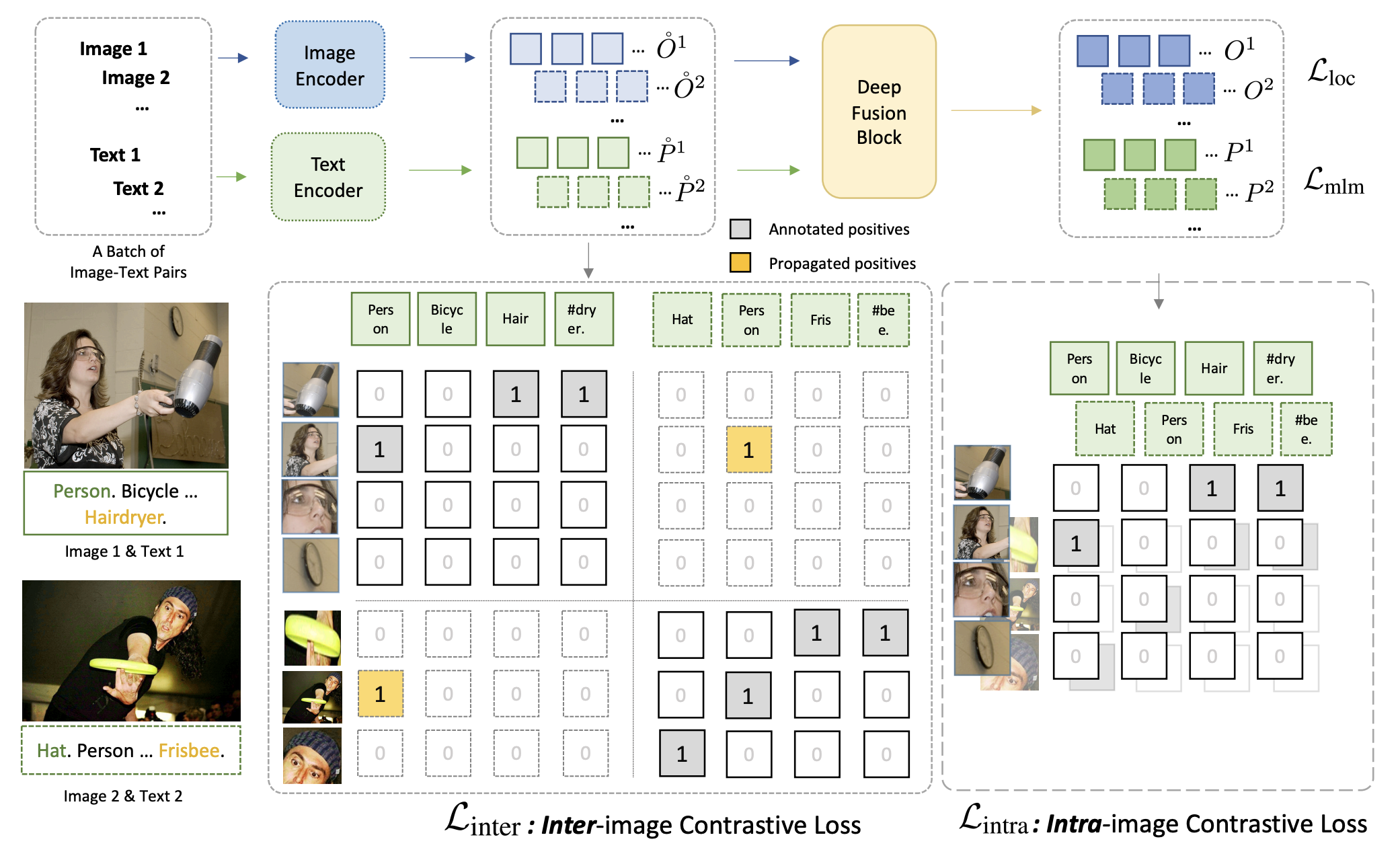 |
|---|
| 原論文Figure 2.画像間で領域特徴とテキスト特徴を比較する Inter-image Contrastive Loss はオリジナルのGLIPに対する新規な点. |
Inter-image region-word contrastive learningについて:
- 基本はGLIPのgrounding損失と同じだが,異なる画像間で領域・フレーズのマッチングを行う
- CLIP等のように画像が異なれば全て負例とするのではなく, label propagation を行う
- 同じフレーズが他の画像に付いていれば,画像が異なっても正例として扱う
結果
議論・コメント
- Label propagationの詳細がわからない
- 全く同じ語・フレーズの場合のみ正例とするのか,「関連する」語・フレーズを正例とするのか
関連文献
Tags
vision&language object detection contrastive learning image captioning