Universal Instance Perception As Object Discovery and Retrieval
18 Jun 2023物体検知,個体領域分割など著者らが「実体知覚」と呼ぶ10のタスクを,クエリに応じて物体を発見・検索するタスクとして統一的に扱うモデルUNINEXTを提案.10のタスク・20のベンチマークで評価し,同じパラメータの単一モデルで従来法を上回る精度を達成.
基本情報
@InProceedings{Yan_2023_CVPR,
author = {Yan, Bin and Jiang, Yi and Wu, Jiannan and Wang, Dong and Luo, Ping and Yuan, Zehuan and Lu, Huchuan},
title = {Universal Instance Perception As Object Discovery and Retrieval},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {15325-15336}
}
論文リンク
著者・所属
Bin Yan, Yi Jiang, Jiannan Wu, Dong Wang, Ping Luo, Zehuan Yuan, Huchuan Lu (Dalian University of Technology, ByteDance, HKU, Peng Cheng Laboratory)
新規性
下記10のタスク=実体知覚タスクをクエリに応じて物体を発見・検索するタスクとして統一的に定式化,これを解くモデルUNINEXTを提案.
- 物体検知 (Object detection)
- 個体領域分割 (Instance segmentation)
- 動画個体領域分割 (Video instance segmentation, VIS)
- 複数物体追跡 (Multi-object tracking, MOT)
- 複数物体領域追跡 (Multi-object tracking and segmentation, MOTS)
- 指示表現理解 (Referring expression comprehension, REC)
- 指示表現領域分割 (Referring expression segmentation, RES)
- 指示物体領域分割 (Referring video object segmentation, R-VOS)
- 単一物体追跡 (Single-object tracking, SOT)
- 動画物体領域分割 (Video object segmentation, VOS)
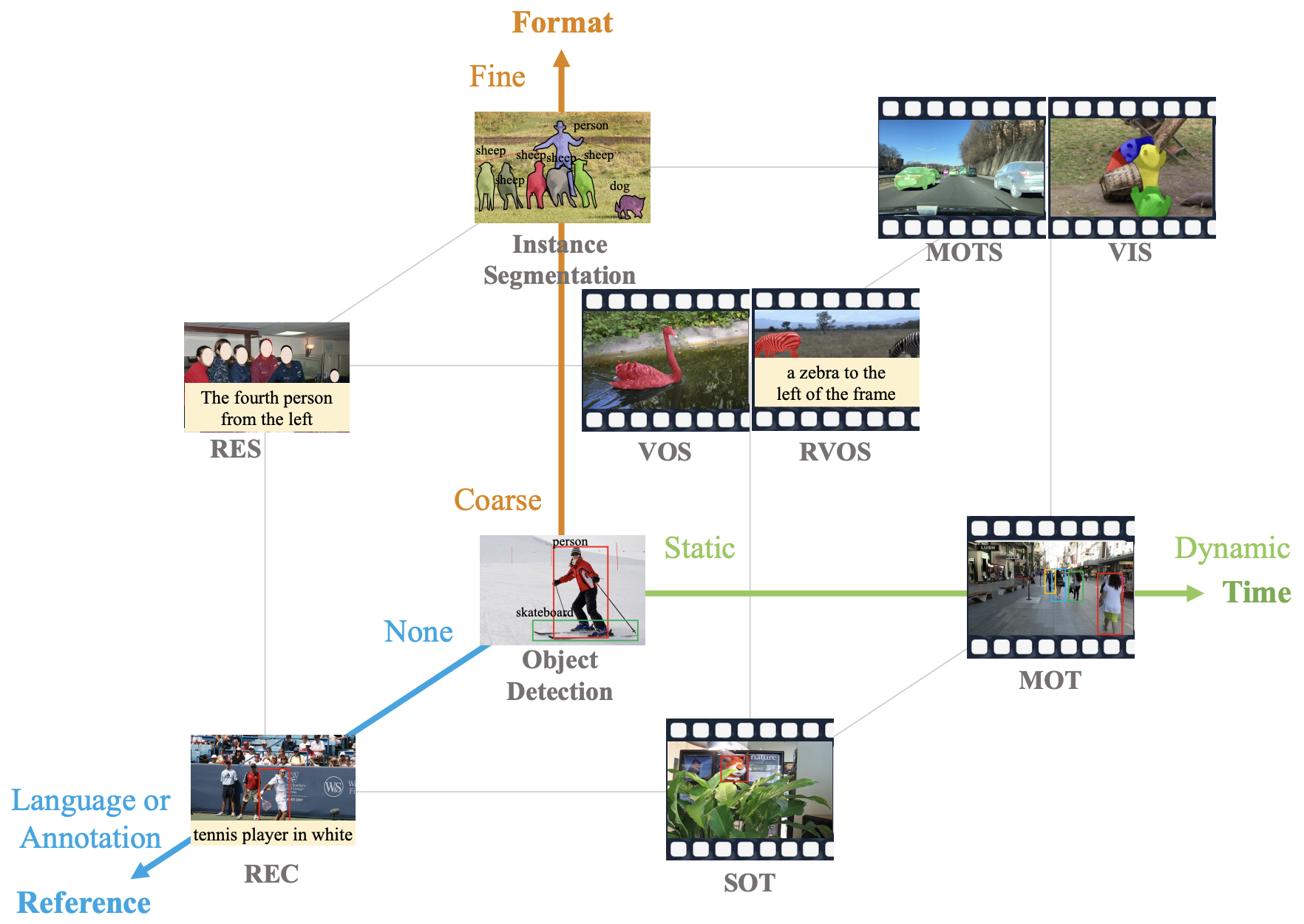 |
|---|
| 原論文Figure 1. 10のタスクを指示の有無(reference),動的か静的か(time),出力のフォーマット(format)の3軸で分類. |
手法
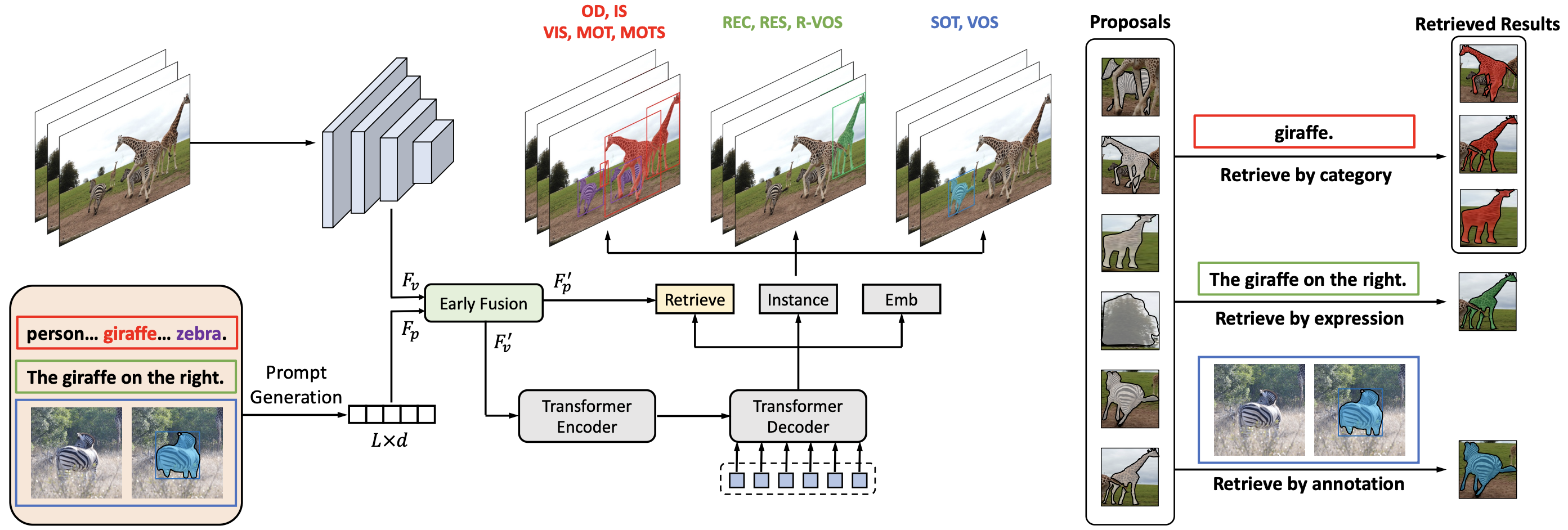 |
|---|
| 原論文Figure 2. モデルの概要. |
10のタスクがいずれもクエリに応じた物体発見・検索タスクとみなせることを考慮し,3つの要素からモデルを構成する:
- プロンプト生成
- 画像・プロンプト融合("Early fusion")
- 双方向交差注意により,画像特徴量とプロンプト特徴量を混ぜる
- 物体発見・検索
- 画像特徴量をTransformerからなるエンコーダ・デーコーダに入力し,$N$個の実体埋め込み(instance embedding)を生成
- Instance headで実体埋め込みをボックスやマスクに変換
- プロンプト特徴量とのマッチングにより出力する実体を選択
- Embedding headはフレーム間で実体を関連付けるために埋め込みを学習する
結果
議論・コメント
- (備忘メモ)ゼロショット系の論文を読んだ後だったのでuniversalという単語に何となくそっち系のニュアンスを読み取ってしまったが,ここでのuniversalはどんなタスクでも(教師あり学習で)解けるモデルという意味だった
- Appendixにopen-vocabはスコープ外と明確に書いてあった
- が,そういう研究ももうやっているだろうとは思う
- (感想)モデル自体は思いの外シンプルだった
- 個々のタスクにおける性能評価で従来法を上回った要因は正直よくわからない
- バックボーンを大きくした時の性能差が一番大きい
関連文献
Tags
foundation models vision&language instance segmentation video object segmentation object detection semantic segmentation