Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers
16 Jun 2023語彙を限定しない物体検知に向けた事前学習方法としてCLIP型のテキスト・画像対照学習アルゴリズム RO-ViT を提案.画像単位でキャプションが付いているデータで画像に局在する物体の表現を学習するため,位置埋め込みをクロップして足し合わせる.
基本情報
@InProceedings{Kim_2023_CVPR,
author = {Kim, Dahun and Angelova, Anelia and Kuo, Weicheng},
title = {Region-Aware Pretraining for Open-Vocabulary Object Detection With Vision Transformers},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {11144-11154}
}
論文リンク
著者・所属
Dahun Kim, Anelia Angelova, Weicheng Kuo (Google Brain)
新規性
物体検知等の局在化向け自己教師あり学習方法としては,従来,マスク付き画像モデリングや対照学習が研究されてきたのに対して,ゼロショット向けの画像・テキスト事前学習は十分に研究されていない.
画像・テキスト事前学習を物体検知に応用した従来研究との比較では,従来研究が事前学習済みモデルを所与のものとしてそれをいかに適応・ファインチューニングするかを議論してきたのに対して,本論文は事前学習方法自体の改良に焦点を当てている.
手法
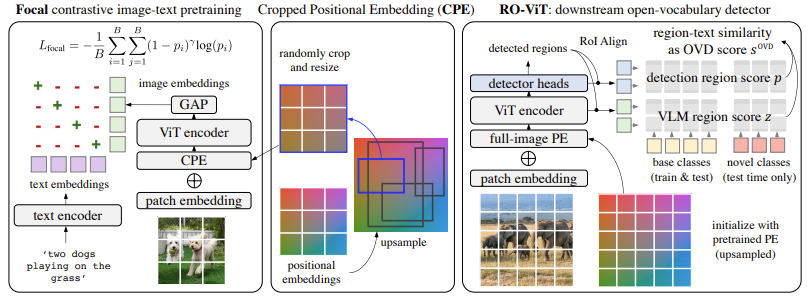 |
|---|
| 原論文Figure 2. RO-ViTの概略. |
事前学習としてはCLIPのような画像・テキスト対照学習を行うが,以下の2点に差異がある.
Cropped Positional Embedding (CPE)
画像単位でキャプションが付いているデータを使って事前学習する.一方,物体検知では画像中の狭い領域にある物体に関心がある.そのような物体に物体検知を行う際には本来その局所領域に対応した位置埋め込みが足しあわされる.そこで,事前学習段階でも画像全体に対応する位置埋め込みではなく,ランダムにクロップした位置埋め込みを用いる.
Focal loss
対照学習の損失関数として交差エントロピーの代わりにfocal損失関数を用いる.
結果
議論・コメント
関連文献
Tags
vision&language object detection