BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
13 Jun 2023画像とテキストを使った事前学習BLIPの論文.従来法が生成タスクと認識タスクの一方に強く他方に弱い点を改善するNNアーキテクチャと,学習したフィルターによってノイジーなキャプション情報を除去しクリーンなデータを学習する機構を導入.
基本情報
@misc{li2022blip,
title={BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation},
author={Junnan Li and Dongxu Li and Caiming Xiong and Steven Hoi},
year={2022},
eprint={2201.12086},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
論文リンク
著者・所属
Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi (Salesforce)
新規性
- 生成タスクと認識タスクの両方で有効なNNアーキテクチャ multimodal mixture of encoder-decoder (MED)
- ウェブから収集したノイジーな画像・キャプションペアと生成したキャプションをフィルタリングしてクリーンなデータを学習するCapFilt
手法
 |
|---|
| 原論文のFigure 2. |
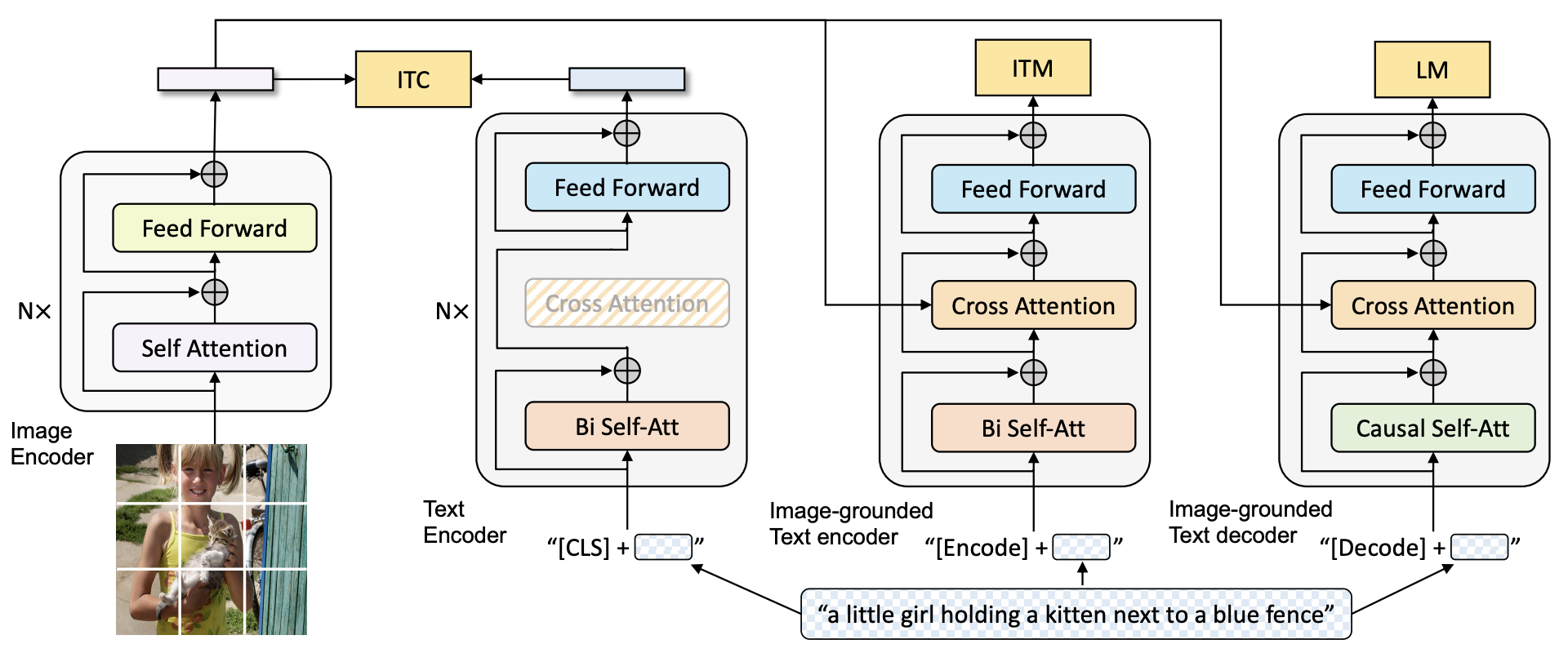
- MEDの構成(Figure 2)
- Unimodal encoder: 画像とテキストをそれぞれ独立に特徴抽出するエンコーダ
- Image-grounded text encoder: 画像特徴量で条件付けされたテキストエンコーダ
- Image-grounded text decoder: 画像特徴量で条件付けされたキャプション生成器
- 2つのテキスト・エンコーダとテキスト・デコーダは部分的に重みを共有している
- 目的関数
- Image-text contrastive (ITC)損失:Align before fuseに倣った画像とテキストの対照損失,unimodal encoderを最適化
- Image-text matching (ITM)損失:画像とテキストが対応しているかどうかの2値分類,image-grounded text encoderを最適化
- Language modeling (LM)損失:キャプション生成の損失,image-grounded text decoderを最適化
 |
|---|
| 原論文のFigure 3. |
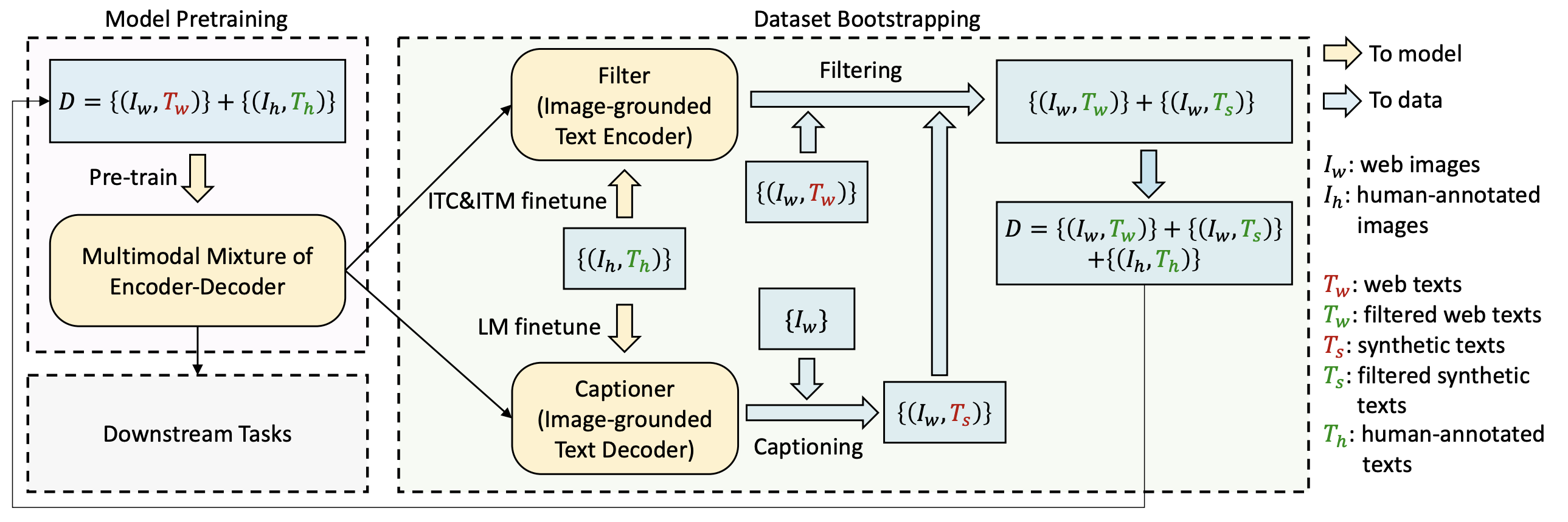
- 学習方法(Figure 3)
- ウェブデータと人手で正解づけした画像・テキストペアを使いMEDを学習
- 前段階の結果を初期値とし,人手で正解づけしたデータを使いfilterとcaptionerをfine-tuning
- Captionerでデータを増やす
- Filterでウェブデータと自動生成したキャプションをフィルタリング
- フィルターしたデータを追加して最初に戻る
結果
議論・コメント
関連文献
Tags
foundation models vision&language