Learning Transferable Visual Models From Natural Language Supervision
10 Jun 2023CLIPの原論文.画像・テキストペアを用い,画像とテキストの埋め込みの間で対照学習を行う.類似の先行研究と比較して,4億の画像・テキストペアという大規模データにスケールさせる設計と,ゼロショット転移でタスクによっては教師あり学習に匹敵する性能を実現した点が貢献.
基本情報
@InProceedings{pmlr-v139-radford21a,
title = {Learning Transferable Visual Models From Natural Language Supervision},
author = {Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {8748--8763},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/radford21a/radford21a.pdf},
url = {https://proceedings.mlr.press/v139/radford21a.html}
}
論文リンク
著者・所属
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever (OpenAI)
新規性
画像とテキストで共通の埋め込み空間を学習するContrastive Language-Image Pre-training (CLIP)を提案.ConVIRT等の類例と比較して,4億の画像・テキストペアにスケールさせ,ゼロショットで様々な顆粒タスクを解ける性能を獲得した点が新しい.さらに30以上のデータセットからなる評価スイートを提案し,50以上の手法と比較評価を実施した.
手法
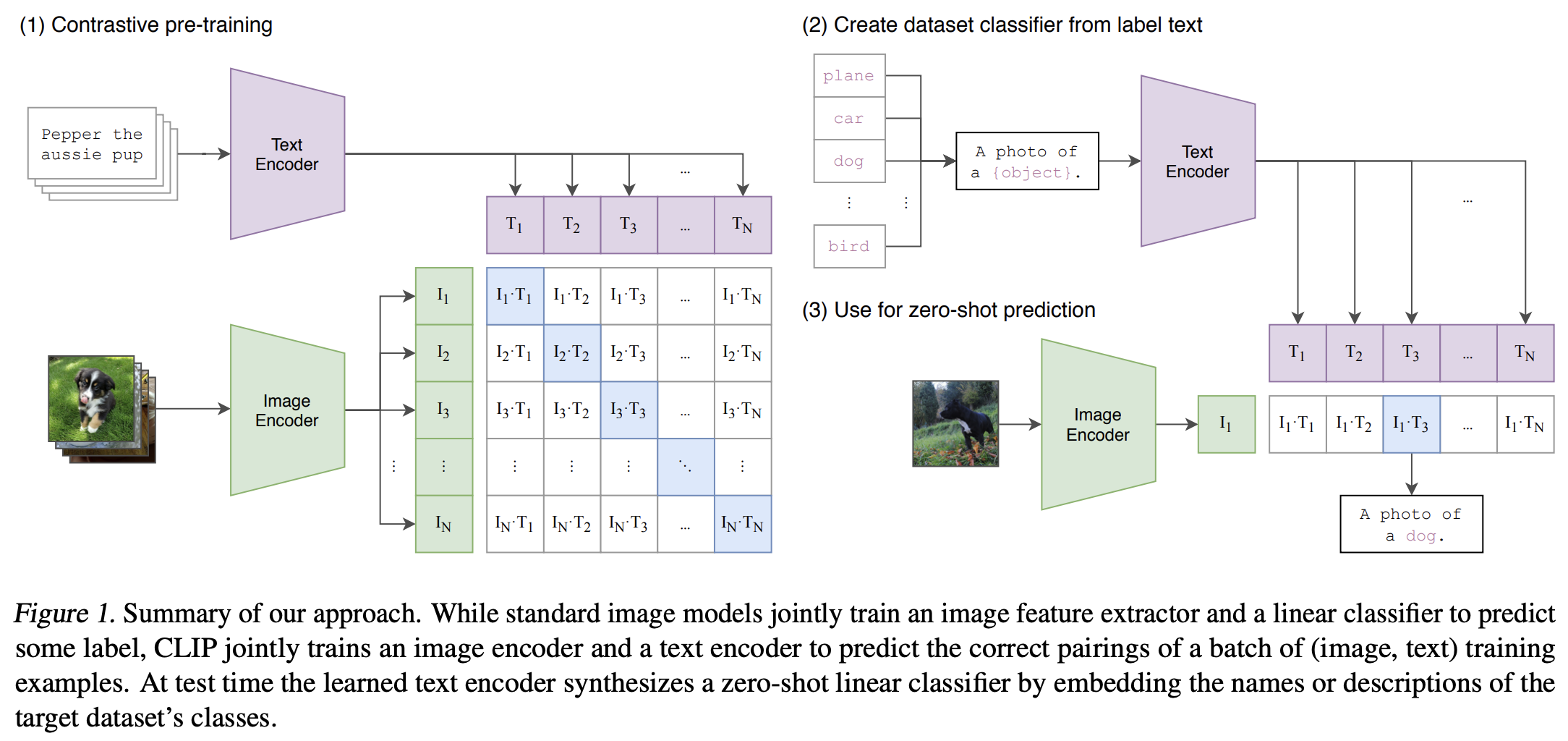 |
|---|
| 原論文Figure 1. 手法の概要. |
- バッチに含まれる画像・テキストペアの画像とテキストをそれぞれ画像エンコーダとテキストエンコーダで埋め込み
- 各画像埋め込みに対して,バッチ中のテキスト埋め込みのうちどれが画像とペアになっていたテキストの埋め込みかを当てる対照学習タスクで2つのエンコーダを学習
- ゼロショット予測時には,クラス名をテキストエンコーダに入れてあらかじめ埋め込みを計算,入力画像に対して計算した画像埋め込みから最も似ているテキスト埋め込みを予測結果として出力する
元々は対照学習ライクなタスクではなくキャプショニングタスクを使った実験をしたが,あまりうまくいかなかったとのこと.テキストを一字一句正確に予測できるようフィットするより,キャプションをテキスト埋め込みとして抽象化したものを当てに行く方が良いとのこと.
結果
- 従来のテキストを使ったゼロショット学習とCLIPのゼロショット学習とを比較すると大きな精度向上
- データセットによってはCLIPのゼロショット転移学習が教師あり線形プローブを超える/匹敵する性能
- CLIPを線形プローブしても強い
- 分布シフトに対して(教師ありよりも)頑健
- 直接教師あり学習すると正解ラベルと入力特徴との間にある擬似相関の影響を直接的に受けるのに対して,ゼロショット転移ではその影響を受けないため?
議論・コメント
- ゼロショットCLIPがone-shot線形プローブよりも性能良いのは面白い
- そもそも分類を行う機構が異なるのでありえないことではない
- 読みながら気になっていたことがLimitationのところに正直に書かれていた
- ゼロショットで線形プローブに匹敵する精度が出るがSOTAに比べると全然弱いとか
- SOTAにも勝つには非現実的なまでに大規模化する必要があるとか
- ゼロショットとは言いつつ検証データを使ってチューニングしちゃってるとか
関連文献
Tags
foundation models vision&language contrastive learning