Segment Anything
16 May 2023領域分割向けの基盤モデルの構築を目指し,プロンプト可能領域分割タスクを提案.このタスクを学習したモデルは,プロンプト・エンジニアリングによって様々な種類の領域分割タスクをゼロショットで解けると期待される.また,このタスク向けのモデルとデータセットを構築し,その性能を評価した.
基本情報
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
論文リンク
Paper / Project Site / Meta Official Blog / Meta Research / GitHub
著者・所属
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, Ross Girshick (META AI Research)
新規性
領域分割向けの基盤モデルを提案した.特に,それを学習するためのタスクとしてプロンプト可能領域分割タスク,このタスクを学習するSegment Anything Model (SAM),そのための訓練データセット (SA-1B) を構築するデータ・エンジンを提案.
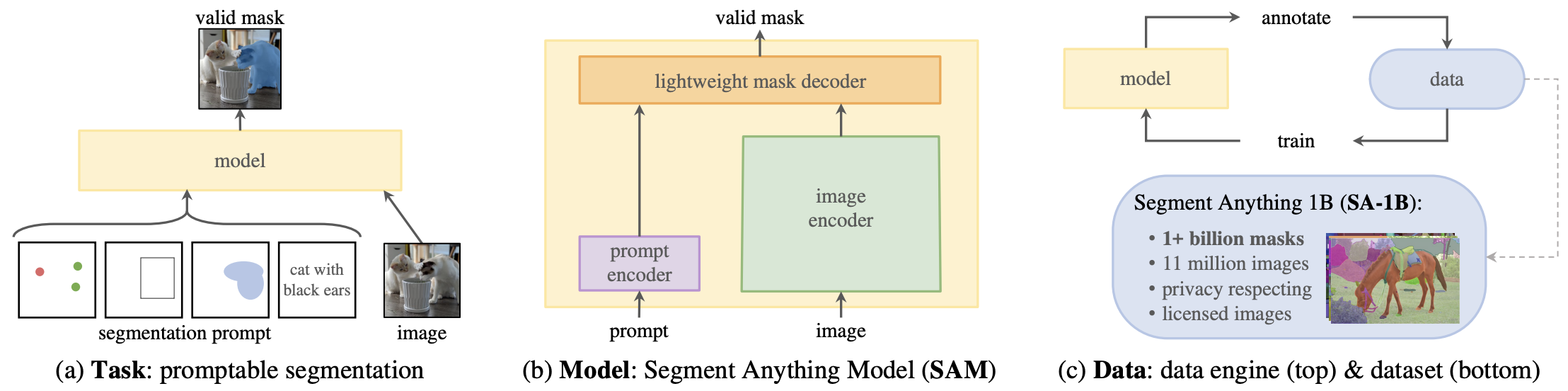 |
|---|
| 原論文のFigure 1. |
手法
タスク,モデル,データの各要素についてまとめる.
タスク
プロンプト可能領域分割は,プロンプトと画像を入力し,妥当な分割マスクを出力するタスクである.ここでのプロンプトは,前景/背景に含まれる点集合,大まかなバウンディングボックスやマスク,テキスト情報など,どの領域をマスクすべきか伝える情報であれば何でも良い.「妥当な」マスクという要件は,曖昧なプロンプトに対してもそれが指し示す一つの尤もらしい領域を返すという程度の意味で,強くは規定されていない.
これが解けるということは,適切にプロンプトを与えることでモデルの挙動を制御できるということである.したがって,プロンプト可能領域分割を学習したモデルはプロンプト・エンジニアリングにより様々な種類の領域分割タスクに適応できる,すなわち領域分割の基盤モデルとなることが期待される.
モデル
提案モデルである Segment Anything Model (SAM) は,ViTからなる画像エンコーダ,各種プロンプト用のプロンプト・エンコーダ,マスクを出力するマスク・デコーダからなる.
- 画像エンコーダ
- MAEで事前学習したViT
- 高解像度処理を実現するため,ViTDetで採用されているのと同じ修正を適用
- プロンプト・エンコーダ
- マスク・デコーダ
- 画像埋め込み,プロンプト埋め込み,出力トークンを入力とするTransformerデコーダ x 2ブロック
- 出力トークはMLPによって線形分類器の重みに変換され,その線形分類器でアップサンプリングした画像埋め込みを前景マスクに分類する
- レイテンシがCPUで50ms程度となるくらいには軽量
- 画像埋め込み,プロンプト埋め込み,出力トークンを入力とするTransformerデコーダ x 2ブロック
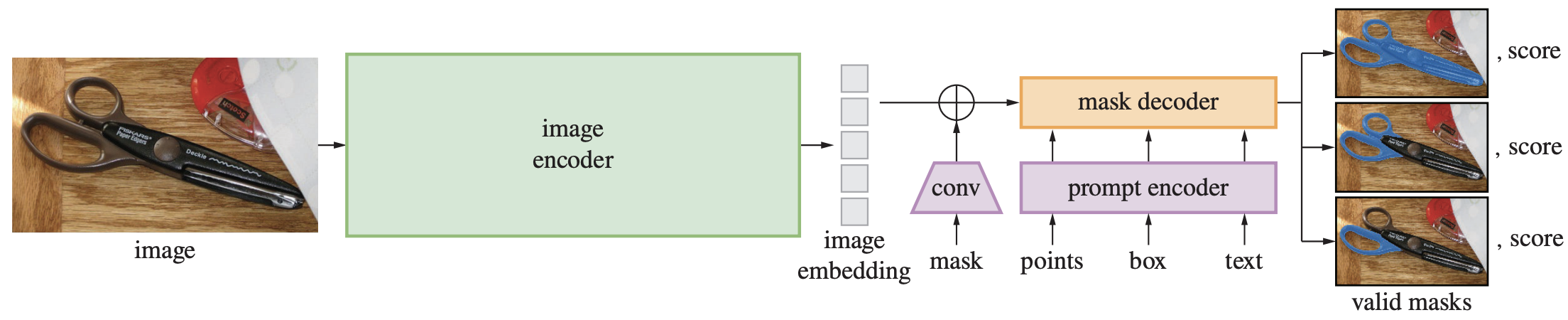 |
|---|
| 原論文のFigure 4. |
データ
プロンプト可能領域分割を学習するための大規模データセットを構築するために,3段階からなる「データ・エンジン」を構築した.
- 補助付き手動アノテーション
- 公開データセットを使って学習済みのSAMで生成したマスクを人力で修正する
- データを増やしながら,SAMを再学習(6回)
- モデルは順次大規模化
- 4.3Mマスク,120k画像
- 半自動アノテーション
- 自動でマスクを生成
- アノテータに自動生成したマスクを見せて,「それ以外の領域」をマスクするよう指示
- 第1段階と合わせて10.2Mマスク,300k画像を追加
- 全自動アノテーション
- グリッド点をプロンプトとしてSAMでマスクを生成
- 信頼度が高い,NMSで残ったマスクを採用
- 拡大して小さい領域のマスクを増やす等の工夫
- 最終的に1.1Bマスク,11M画像
結果
さまざまなゼロショットタスクで評価.実験セクションはSAM向けプロンプト・エンジニアリングの参考になる.詳細は割愛するが,気になった結果だけ簡単に触れる.
- インスタンス・セグメンテーションでは,mask APこそ教師あり学習に劣るものの,マスク品質の主観評価ではゼロショットのSAMが優れている
- 教師データの品質が悪く,教師あり学習はその影響を直接受けてしまうため?
- データ・エンジンの3段階は,段階を踏むごとにSAMの精度が上がる
- 一方で,データ量でみると10分の1(1M画像程度)で精度がサチる
議論・コメント
関連文献
- ViTDet
- SAMのバックボーンにはViTDetで提案された修正版ViTを採用している
- 実験パートでは比較対象に使われている
Tags
foundation models instance segmentation promptable vision models