BEVT: BERT Pretraining of Video Transformers
14 May 2023BERT型マスク付き動画モデリングに基づく事前学習を動画データに適用した初期の論文.基本的な構成は静止画用のBEiTを参考にしているが,動的性質と静的性質を切り分けて学習するために重みを共有する動画用エンコーダと静止画用エンコーダを同時に学習するのが特徴.
基本情報
@inproceedings{wang2021bevt,
title={BEVT: BERT Pretraining of Video Transformers},
author={Wang, Rui and Chen, Dongdong and Wu, Zuxuan and Chen, Yinpeng and Dai, Xiyang and Liu, Mengchen and Jiang, Yu-Gang and Zhou, Luowei and Yuan, Lu},
booktitle={CVPR},
year={2022}
}
論文リンク
著者・所属
Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Yu-Gang Jiang, Luowei Zhou, Lu Yuan (Fudan Univeristy, Microsoft Cloud+AI)
新規性
Image streamとvideo streamを持つtwo-stream構造で動画の静的特徴と動的特徴を効率よく学習できる,BERT型の事前学習手法を提案.
手法
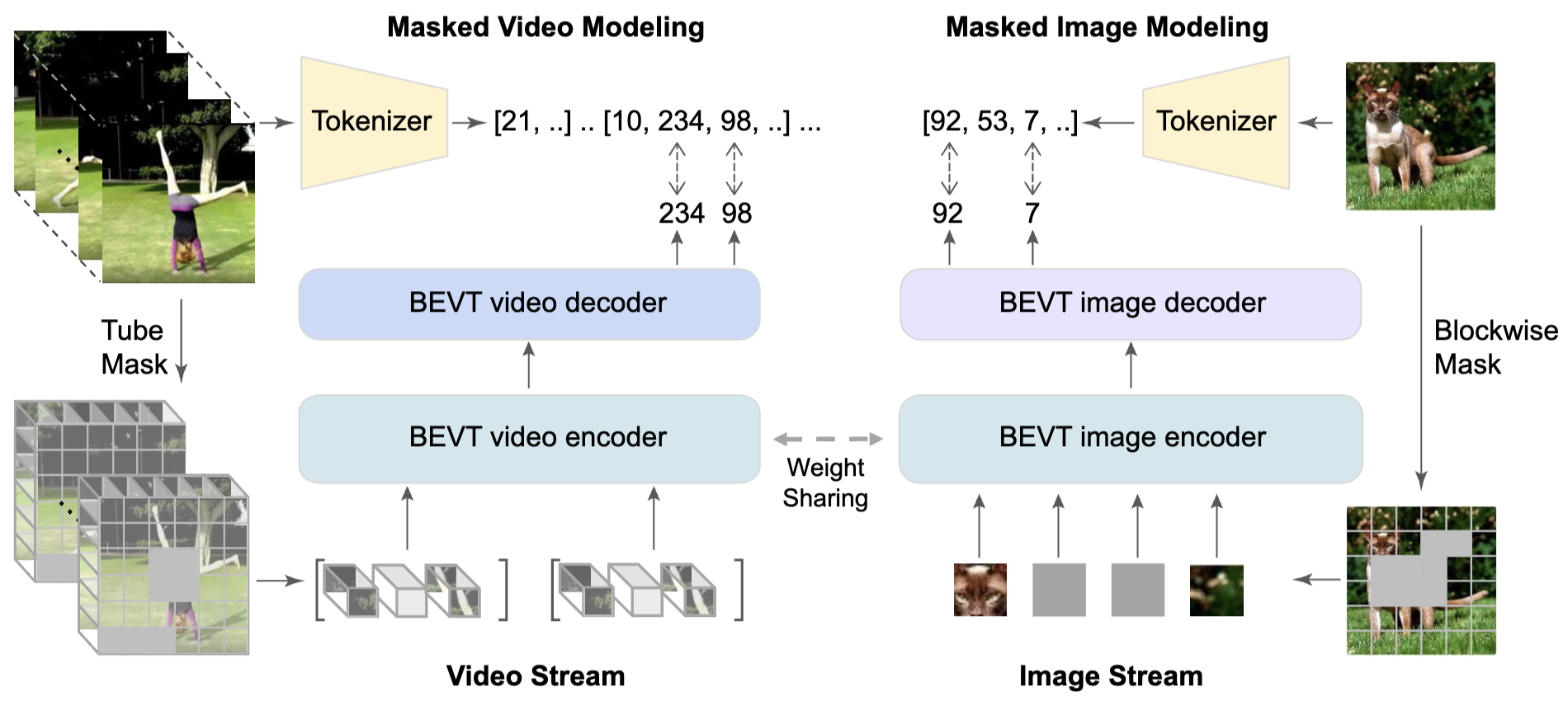 |
|---|
| BEVTの概要(原論文Figure 2) |
再構成ターゲットとして事前学習済みの離散VAEが出力するトークンを利用する点など,主要な部分ではBEiT(メモ)を踏襲している.BEVTではさらに,静止画を入力とするimage streamと動画を入力とするvideo streamのtwo-stream構成を採用.2つのstreamは入力をパッチ・トークン化する層を除き全ての重みを共有する.これらに対して2段階の学習を行う:
- Image streamの学習
- Video streamとimage streamの同時学習
要するに1つのTransformerエンコーダを静止画データと動画データの両方使って学習するためのtwo-stream構成.Video streamだけでスクラッチから学習するより効果的という主張.
結果
議論・コメント
Ablation studyを見ると,静止画データでの事前学習と動画データでの事前学習のどちらが効いているかは評価データによってまちまち.2段階学習の第1段階の必要性はよくわからない.
関連文献
Tags
video self-supervised learning