InternVideo: General Video Foundation Models via Generative and Discriminative Learning
29 Apr 2023動画データ向け基盤モデル InternVideo の論文.生成的自己教師あり学習(マスク動画モデリング)と識別的自己教師あり学習(CLIPに似た対照学習)でそれぞれ学習した2つのエンコーダをクロス・モデル・アテンションにより統合する.行動認識,動画・言語タスク,オープン・ワールド動画理解など各種の動画タスクで2023年4月現在Paper With Codeの上位にランクインする.
基本情報
@article{wang2022internvideo,
title={InternVideo: General Video Foundation Models via Generative and Discriminative Learning},
author={Wang, Yi and Li, Kunchang and Li, Yizhuo and He, Yinan and Huang, Bingkun and Zhao, Zhiyu and Zhang, Hongjie and Xu, Jilan and Liu, Yi and Wang, Zun and Xing, Sen and Chen, Guo and Pan, Junting and Yu, Jiashuo and Wang, Yali and Wang, Limin and Qiao, Yu},
journal={arXiv preprint arXiv:2212.03191},
year={2022}
}
論文リンク
著者・所属
- Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jashuo Yu, Hongjie Zhang, Yali Wang, Limin Wang, and Yu Qiao (Shanghai AI Lab)
新規性
動画タスク向け基盤モデルの枠組みを提案.技術的には,マルチ・モデル・アテンションによって2種類の事前学習済みモデルを統合する手法に新規性があると思われる.
手法
4ステップで学習する.
- 自己教師あり表現学習
- マスク自己回帰モデルとマルチモーダル対照学習を独立に実施し2つのエンコーダを学習する
- マスク自己回帰モデルはVideoMAEベースでViTを学習
- マルチモーダル対照学習はCLIPにalign-before-fuseに則りキャプショニングを付け足したようなもの,アーキテクチャはUniFormerV2
- 教師あり学習
- 前ステップで学習したエンコーダをKineticsでファイン・チューニング
- これも2つのエンコーダに対して独立に実施する
- クロス・モデル・アテンションによる2つのエンコーダの統合
- 下流タスクの学習
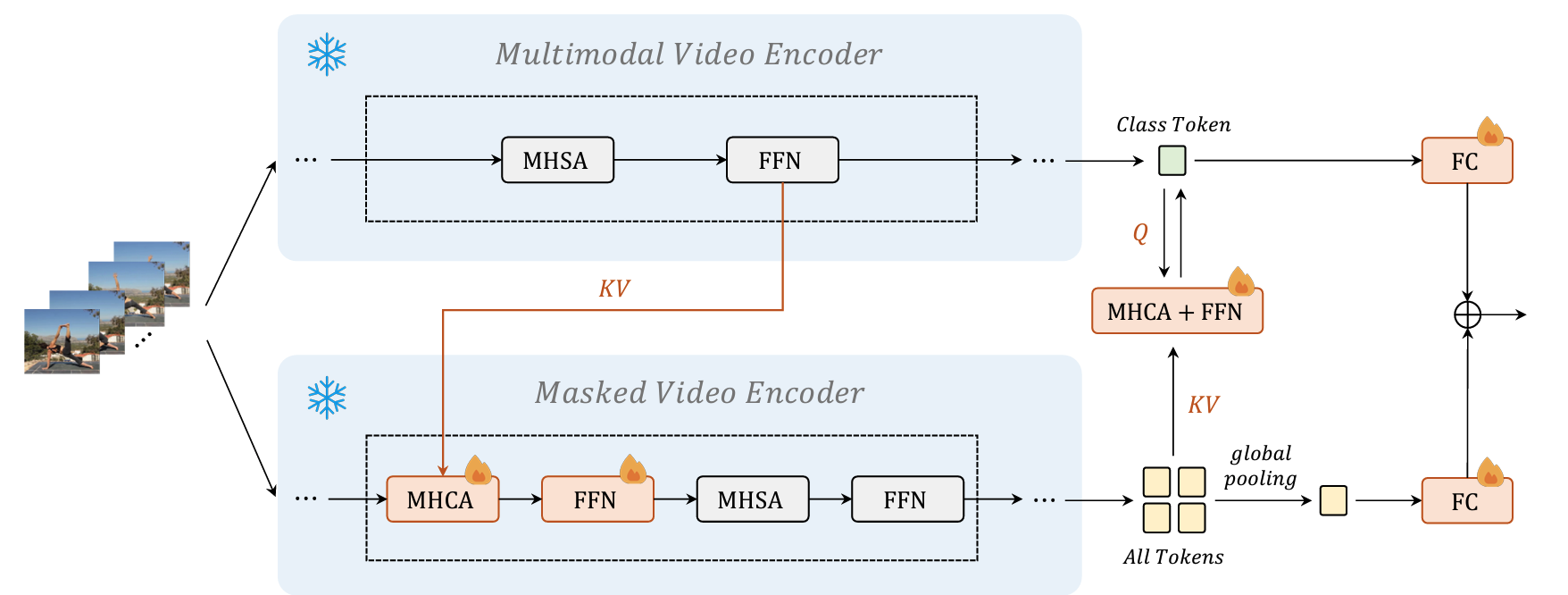 |
|---|
| 原論文のFigure 4.2種類のエンコーダを統合するクロス・モデル・アテンションの概要.火のアイコン(?)が付いている層のパラメータを更新し,その他の層は事前学習済みのパラメータを固定する. |
結果
- Paper With Codeでは様々なタスクの上位にランクインしている(2023/4現在)
- 特にECCV2022のEgo4D WSにおいて5つのチャレンジで優勝した
議論・コメント
おそらくクロス・モデル・アテンションの部分が技術的な新規性と思われるが,肝心のその部分について学習データや最適化のハイパーパラメータなど詳細な情報(4/29追記:最適化については4.2.3に記述があった)を読み取れなかった.学会やジャーナルに採択された論文ではなく技術報告書としてarXivに掲載されているので,今後の更新に期待?
関連文献
- VideoMAE
- CoCa
- Align before fuse
- ViT, ViViT, UniFormerV2
Tags
foundation models video vision&language self-supervised learning